16º-24º
lunes | 18 agosto | 2025
16º-24º
lunes | 18 agosto | 2025

Una nueva investigación ha arrojado luz sobre la capacidad de los modelos de inteligencia artificial para reproducir textualmente contenido de material protegido por derechos de autor.
En concreto, el modelo Llama 3.1 70B de Meta ha "memorizado" una parte significativa del primer libro de Harry Potter. Este hallazgo plantea importantes interrogantes en el creciente número de demandas por derechos de autor contra empresas de IA.
El estudio, publicado el mes pasado por un equipo de científicos informáticos y expertos legales de Stanford, Cornell y la Universidad de West Virginia, examinó la capacidad de cinco modelos de código abierto populares, incluidos tres de Meta, para reproducir texto de Books, una colección de libros utilizada comúnmente para entrenar Grandes Modelos de Lenguaje (LLM). Muchos de estos libros aún están protegidos bajo derechos de autor.
El descubrimiento más sorprendente del informe es que Llama 3.1 70B, un modelo de tamaño mediano lanzado por Meta en julio de 2024, es mucho más propenso a reproducir texto de "Harry Potter y la Piedra Filosofal" que otros modelos analizados.
Específicamente, el estudio estima que Llama 3.1 70B ha memorizado el 42 por ciento del primer libro de Harry Potter lo suficientemente bien como para reproducir extractos de 50 tokens al menos la mitad de las veces.
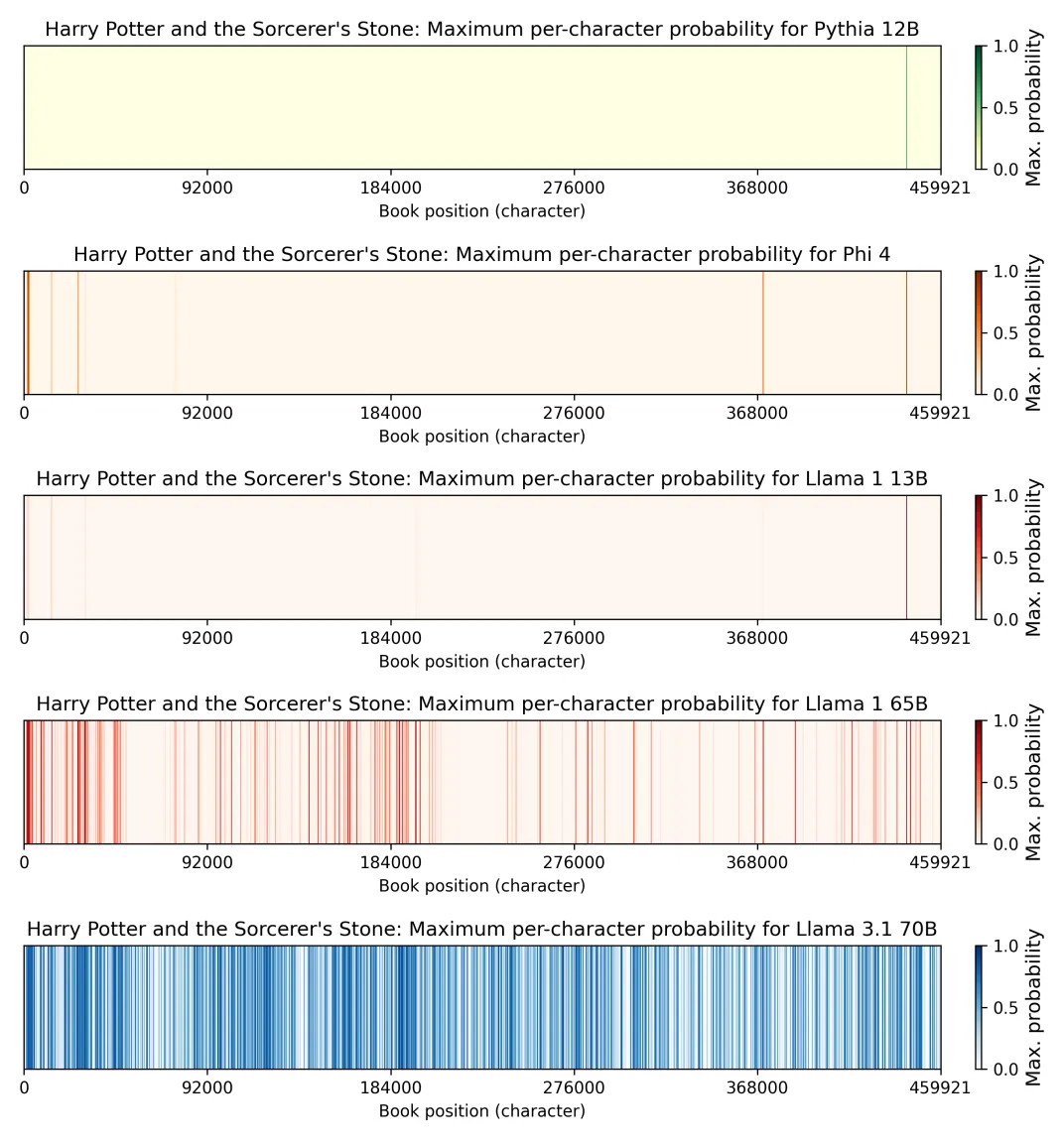
En contraste, Llama 1 65B, un modelo de tamaño similar lanzado en febrero de 2023, solo había memorizado el 4,4 por ciento del mismo libro. Esto sugiere que, a pesar de las posibles implicaciones legales, Meta no hizo mucho para evitar la memorización al entrenar Llama 3, y el problema empeoró entre Llama 1 y Llama 3 para este libro.
Los investigadores también encontraron que Llama 3.1 70B era significativamente más propenso a reproducir libros populares como "El Hobbit" de J.R.R. Tolkien y "1984" de George Orwell, en comparación con obras menos conocidas. Y para la mayoría de los libros, Llama 3.1 70B memorizó más que cualquiera de los otros modelos.
James Grimmelmann, profesor de derecho en Cornell y colaborador de algunos de los autores del estudio, destacó las "diferencias realmente sorprendentes entre los modelos en términos de cuánto texto literal han memorizado".
El propio Mark Lemley, profesor de derecho en Stanford y coautor del estudio, expresó su sorpresa ante los resultados. "Esperábamos ver algún tipo de bajo nivel de replicabilidad del orden del 1 o 2 por ciento", señaló Lemley, añadiendo que "lo primero que me sorprendió es cuánta variación hay".
Este estudio llega en un momento clave, con numerosas demandas presentadas por editores y otros creadores contra empresas de IA por el uso de material protegido por derechos de autor en el entrenamiento de sus modelos.
Una pregunta central en estos litigios es la facilidad con la que los modelos de IA producen extractos textuales del contenido con derechos de autor.
The New York Times Company, por ejemplo, presentó docenas de ejemplos en los que GPT-4 de OpenAI reprodujo pasajes significativos de sus historias en su demanda de diciembre de 2023. OpenAI, por su parte, calificó esto como un "comportamiento marginal" y un "problema que los investigadores de OpenAI y otros trabajan arduamente para abordar".
Los hallazgos de este nuevo estudio complican esa narrativa. Para los críticos de la industria de la IA, la principal conclusión es que, al menos para algunos modelos y libros, la memorización no es un fenómeno marginal.
Sin embargo, el estudio también ofrece argumentos para la defensa, ya que solo encontró una memorización significativa en un puñado de libros populares. Por ejemplo, los investigadores encontraron que Llama 3.1 70B solo memorizó el 0,13 por ciento de "Sandman Slim", una novela de 2009 del autor Richard Kadrey, una fracción minúscula comparada con el 42 por ciento de Harry Potter.

Estas diferencias en la memorización podrían dificultar la certificación de demandas colectivas, ya que los tribunales requieren que los demandantes se encuentren en situaciones legales y fácticas en gran medida similares. Esto podría jugar a favor de Meta, dado que la mayoría de los autores carecen de los recursos para presentar demandas individuales.
Existen tres teorías principales sobre cómo el entrenamiento de un modelo con obras protegidas por derechos de autor podría infringir el copyright:
Si bien la industria de la IA argumenta que el uso de obras protegidas por derechos de autor durante el entrenamiento es un "uso justo" bajo el fallo de Google Books de 2015, la capacidad de Llama 3.1 70B para regurgitar grandes porciones de obras populares como "Harry Potter", "1984" y "El Hobbit" podría hacer que los jueces vean estos argumentos con más escepticismo.
Además, uno de los argumentos clave de Google en el caso de los libros fue que su sistema estaba diseñado para no devolver más de un breve extracto de cualquier libro. Si el juez en la demanda contra Meta quisiera distinguir los argumentos de Meta de los que Google presentó, podría señalar el hecho de que Llama puede generar mucho más que unas pocas líneas de Harry Potter.
El nuevo estudio "complica la historia que los demandados han estado contando en estos casos", según el coautor Mark Lemley, que es "simplemente aprendemos patrones de palabras. Nada de eso aparece en el modelo".
El resultado de Harry Potter crea aún más peligro para Meta bajo la segunda teoría legal: que Llama es una copia derivada del libro de Rowling.
"Está claro que de hecho se pueden extraer partes sustanciales de Harry Potter y de otros libros del modelo", dijo Lemley. Esto sugiere que "probablemente para algunos de esos libros hay algo que la ley llamaría una copia de parte del libro en el modelo mismo".
El precedente de Google Books probablemente no puede proteger a Meta contra esta segunda teoría legal, porque Google nunca puso su base de datos de libros a disposición de los usuarios para que la descargaran.
Los autores del estudio aún no tienen una explicación definitiva de por qué Llama 3.1 70B memorizó tanto "Harry Potter y la Piedra Filosofal". Una hipótesis es que Llama 3 70B fue entrenado con 15 billones de tokens, más de 10 veces los 1,4 billones de tokens utilizados para entrenar Llama 1 65B. Cuantas más veces se entrena un modelo con un ejemplo particular, más probable es que lo memorice.
Podría ser que Meta tuvo dificultades para encontrar 15 billones de tokens distintos y entrenó con el conjunto de datos Books3 varias veces, o que incluyó fuentes de terceros como foros de fans o reseñas de libros que citaban extensamente estas obras populares.

Sin embargo, la magnitud de la memorización de Harry Potter sigue siendo sorprendente. Lemley señaló que si se tratara solo de citas, se esperaría que se concentraran en unos pocos pasajes populares. El hecho de que Llama 3 haya memorizado casi la mitad del libro sugiere que el texto completo estuvo bien representado en los datos de entrenamiento.
También podría haber otra explicación, como cambios sutiles en la receta de entrenamiento de Meta que accidentalmente empeoraron el problema de la memorización. Mark Lemley comentó que "no parece ser en todos los libros populares. Algunos libros populares tienen este resultado y otros no. Es difícil encontrar una historia clara que diga por qué sucedió eso".
La investigación también destaca una posible "perversidad" en el sistema legal: podría desincentivar a las empresas a lanzar modelos de código abierto.
Los investigadores solo pudieron realizar este estudio porque tuvieron acceso al modelo subyacente de Llama y, por lo tanto, a los valores de probabilidad de los tokens que permitieron un cálculo eficiente de las probabilidades para secuencias de tokens.
La mayoría de los laboratorios líderes, incluidos OpenAI, Anthropic y Google, han restringido cada vez más el acceso a estos "logits", lo que dificulta el estudio de sus modelos. Además, si una empresa mantiene los pesos del modelo en sus propios servidores, puede usar filtros para tratar de evitar que la salida infractora llegue al mundo exterior.
Así, incluso si los modelos subyacentes de OpenAI, Anthropic y Google han memorizado obras protegidas por derechos de autor de la misma manera que Llama 3.1 70B, podría ser difícil para cualquier persona fuera de la empresa demostrarlo.
Este tipo de filtrado también facilita que las empresas con modelos de peso cerrado invoquen el precedente de Google Books. En resumen, la ley de derechos de autor podría crear un fuerte desincentivo para que las empresas lancen modelos de código abierto.
A pesar de esta preocupación, Lemley y Grimmelmann reconocen que los jueces podrían concluir que sería perjudicial castigar a las empresas por publicar modelos de código abierto. Grimmelmann comentó que "hay un grado en que ser abierto y compartir pesos es una especie de servicio público", y añadió que "honestamente, podría ver a los jueces siendo menos escépticos con Meta y otros que proporcionan modelos de peso abierto".
El estudio subraya que los detalles serán cruciales en estos casos de derechos de autor, y demuestra que la cuestión de si los modelos generativos copian o simplemente aprenden de sus datos de entrenamiento puede ser probada empíricamente, con resultados que varían según los modelos y las obras protegidas.